Connecting Perl on UNIX or Linux to Microsoft SQL Server
Contents
- Prerequisites
- Assumptions
- Testing your ODBC data source
- Where to go now
- Calling procedures
- Multiple Active Statements
- Faster inserting
- Alternative Perl SQL Server solution
Prerequisites
The prerequisite software for this tutorial is:
-
Perl
We used Perl 5.8, but you only need the minimum version required by the DBI and DBD::ODBC modules, which is currently 5.6. Use
perl --versionto find out what version of Perl you have installed. -
DBI module
We used DBI 1.45 and DBI 1.607, but the samples in this tutorial should work with anything after 1.40. To find out if you have a recent enough version of DBI installed, run:
perl -e 'use DBI 1.40;'
If you get an error like "DBI version 1.40 required--this is only version 1.30 at -e line 1," you need to upgrade DBI.
If you get an error saying "DBI cannot be found in @INC," you have probably not got DBI installed.
Go to CPAN to get an up-to-date version of the DBI module.
-
DBD::ODBC
We used DBD::ODBC 1.11 and DBD::ODBC 1.17. You can use similar methods to the ones shown above to check whether DBD::ODBC is installed and to see what version you have.
To check that you have the DBD::ODBC module installed:
perl -e 'use DBD::ODBC;'
If you have not got DBD::ODBC installed, refer to Enabling ODBC support in Perl with Perl DBI and DBD::ODBC for installation instructions.
To show the DBD::ODBC version:
perl -MDBD::ODBC -e 'print $DBD::ODBC::VERSION;'
To show all drivers DBI knows about and their versions:
perl -MDBI -e 'DBI->installed_versions;'
-
SQL Server ODBC driver
We used our SQL Server ODBC driver to connect Perl to a remote SQL Server database:
- Download the SQL Server ODBC driver for your Perl client platform.
If the SQL Server ODBC driver is not currently available for your platform, check the list of ODBC-ODBC Bridge client platforms. The ODBC-ODBC Bridge is an alternative SQL Server solution from Easysoft, which you can download from this site.
- Install and license the SQL Server ODBC driver on the machine where Perl is installed.
For installation instructions, refer to the ODBC driver documentation. Refer to the documentation to find out which environment variables you need to set (
LD_LIBRARY_PATH,LIBPATH,LD_RUN_PATH,SHLIB_PATHdepending on the driver, platform, and linker). - Create an ODBC data source in
/etc/odbc.inithat connects to the SQL Server database you want to access from Perl. For example, this SQL Server ODBC data source connects to a SQL Server Express instance that serves the Northwind database:[MSSQL-Perl] Driver = Easysoft ODBC-SQL Server Server = my_machine\SQLEXPRESS User = my_domain\my_user Password = my_password # If the database you want to connect to is the default # for the SQL Server login, omit this attribute Database = Northwind
- Use isql to test the new data source. For example:
cd /usr/local/easysoft/unixODBC/bin ./isql -v MSSQL-Perl
At the prompt, enter
helpto display a list of tables. To exit, press Return in an empty prompt line.
- Download the SQL Server ODBC driver for your Perl client platform.
Assumptions
-
Operating system
This tutorial was designed on UNIX and Linux, and we have assumed you are using UNIX or Linux too. However, all the Perl examples should work equally well on Windows as long as some minor alterations to the command line are made.
-
ODBC Driver Manager
We assume that you're using the unixODBC Driver Manager.
Testing your ODBC data source
The following script selects and fetches some test data. Use it to check that you can successfully access your ODBC data source from Perl. Remember to replace the data source name and database user name and password placeholders with appropriate values for your database.
#!/usr/bin/perl -w use strict; use DBI; # Replace datasource_name with the name of your data source. # Replace database_user_name and database_password # with the SQL Server database user name and password. my $data_source = q/dbi:ODBC:datasource_name/; my $user = q/database_user_name/; my $password = q/database_password/; # Connect to the data source and get a handle for that connection. my $dbh = DBI->connect($data_source, $user, $password) or die "Can't connect to $data_source: $DBI::errstr"; # This query generates a result set with one record in it. my $sql = "SELECT 1 AS test_col"; # Prepare the statement. my $sth = $dbh->prepare($sql) or die "Can't prepare statement: $DBI::errstr"; # Execute the statement. $sth->execute(); # Print the column name. print "$sth->{NAME}->[0]\n"; # Fetch and display the result set value. while ( my @row = $sth->fetchrow_array ) { print "@row\n"; } # Disconnect the database from the database handle. $dbh->disconnect;
Where to go now
After you've tested your data source, you're ready to start fetching and manipulating the data in your database from Perl. We suggest you check out Introduction to retrieving data from your database or the excellent book "Programming the Perl DBI," which you can find at http://dbi.perl.org.
The rest of this tutorial covers some SQL Server specific issues and common questions from people accessing SQL Server from Perl.
Calling procedures
The following section shows you how to create and call SQL Server procedures that accept input and return output.
To use the sample scripts in this section, you need a SQL Server database in which you can create and delete tables and procedures. The data source that you specify in the scripts needs to connect to this database.
Input parameters
Input parameters are used to supply values to a procedure. For example, a procedure that executes a SELECT statement might use an input parameter to supply a value in a WHERE clause. You provide input parameter values when the procedure is called.
The following example script shows how to create a procedure that accepts one input parameter. The procedure adds 1 to the input parameter value and returns the new value. The script calls the procedure and displays the return value.
#!/usr/bin/perl -w use strict; use DBI; # Replace datasource_name with the name of your data source. # Replace database_user_name and database_password # with the SQL Server database user name and password. my $data_source = q/dbi:ODBC:datasource_name/; my $user = q/database_user_name/; my $password = q/database_password/; my $dbh = DBI->connect($data_source, $user, $password) or die "Can't connect to $data_source: $DBI::errstr"; # This procedure takes one input parameter. It adds 1 to the input # parameter value and returns the new value. $dbh->do(q/CREATE PROCEDURE PROC_RETURN_INPUT_PARAM (@inputval int) AS SET @inputval = @inputval+1; RETURN @inputval;/); # The first placeholder (?) in this prepared statement is used to # capture the return value of the called procedure. The second # placeholder represents the value that's supplied as the procedure's # input parameter. my $sth1 = $dbh->prepare ("{? = call PROC_RETURN_INPUT_PARAM(?) }"); my $output; my $i = 1; # Bind value for the first placeholder. Because the prepared statement # updates the bind value, bind_param_inout rather than bind_param needs # to be used. $sth1->bind_param_inout(1, \$output, 1); # Bind value for second placeholder. This is value for the procedure's # input parameter. $sth1->bind_param(2, $i); # Execute the prepared statement. $sth1->execute(); # Output the procedure's return value. print "$output\n"; $dbh->do(q/DROP PROCEDURE PROC_RETURN_INPUT_PARAM/); $dbh->disconnect;
This example script inserts rows into a table with an identity column and uses @@IDENTITY to display the identity value used in each new row. The identity value is a unique, incremental value that SQL Server automatically generates when a new row is added to the table.
The procedure in the script accepts one input parameter: a value to insert into the new row. The procedure returns the row's identity value.
#!/usr/bin/perl -w use strict; use DBI; # Replace datasource_name with the name of your data source. # Replace database_user_name and database_password # with the SQL Server database user name and password. my $data_source = q/dbi:ODBC:datasource_name/; my $user = q/database_user_name/; my $password = q/database_password/; my $dbh = DBI->connect($data_source, $user, $password) or die "Can't connect to $data_source: $DBI::errstr"; # Create sample table in which to insert test data. The first column is an # identity column. When a new row is added to the table, SQL Server # provides a unique, incremental value for the column so long as that # column value is not specified. $dbh->do(q/CREATE TABLE PERL_SAMPLE_TABLE (a INTEGER identity, b CHAR(1))/); $dbh->do(q/CREATE PROCEDURE PROC_LAST_INSERTED_VALUE (@inputval char) AS INSERT INTO PERL_SAMPLE_TABLE VALUES (@inputval); RETURN @@IDENTITY;/); # The first placeholder (?) in this prepared statement is used to # capture the return value of the called procedure. The second # placeholder represents the value that's supplied as the procedure's # input parameter. my $sth1 = $dbh->prepare ("{? = call PROC_LAST_INSERTED_VALUE(?) }"); my $output = 0; my $char = q/a/; # Insert two records into the table. while ($char ne q/c/) { # Bind value for the first placeholder. Because the prepared statement # updates the bind value, bind_param_inout rather than bind_param needs # to be used. $sth1->bind_param_inout(1, \$output, 100); # Bind value for second placeholder. This is value for the procedure's # input parameter. $sth1->bind_param(2, $char); # Execute the prepared statement. $sth1->execute(); # Display the last generated identity value. print "Identity value for last record = $output\n" if ($output != 0); $char++; } $dbh->do(q/DROP PROCEDURE PROC_LAST_INSERTED_VALUE/); $dbh->do(q/DROP TABLE PERL_SAMPLE_TABLE/); $dbh->disconnect;
Output parameters
A procedure can return information by using either RETURN or output parameters. RETURN lets you return an integer value. Output parameters let you return other types of values from a procedure. For example, character strings and cursors.
Output parameters also let you return more than one value from a procedure. For example, in a procedure that contains multiple INSERT statements, you can use multiple output parameters to capture and return the numbers of rows affected by each statement.
The following sample script illustrates this technique. It uses output parameters to generate a cumulative total of the number of rows affected by statements in a procedure. The script contrasts this total with the one returned by the DBI rows method. The rows method returns the number of rows affected by the last row affecting statement. It's unaware that the example procedure contains more than one INSERT statement. The totals are different therefore. Note that this comment also applies to UPDATE and DELETE statements.
#!/usr/bin/perl -w use strict; use DBI; # Replace datasource_name with the name of your data source. # Replace database_user_name and database_password # with the SQL Server database user name and password. my $data_source = q/dbi:ODBC:datasource_name/; my $user = q/database_user_name/; my $password = q/database_password/; my $dbh = DBI->connect($data_source, $user, $password) or die "Can't connect to $data_source: $DBI::errstr"; # Create sample table in which to insert test data. $dbh->do(q/CREATE TABLE PERL_SAMPLE_TABLE (i INTEGER)/); # This procedure takes one input parameter and two output parameters. # The procedure inserts the input parameter value into a test table. # The output parameters are used to return the number of rows affected # by each INSERT statement. $dbh->do(q/CREATE PROCEDURE PROC_INSERT_TABLES (@inputval int, @rowcount1 int OUTPUT, @rowcount2 int OUTPUT) AS BEGIN -- SET NOCOUNT ON here will prevent DBI rows from returning -- the row count. INSERT INTO PERL_SAMPLE_TABLE VALUES (@inputval); -- @@ROWCOUNT returns the number of rows affected by the -- last statement. Store this number in the first output -- parameter. SET @rowcount1 = @@ROWCOUNT; INSERT INTO PERL_SAMPLE_TABLE VALUES (@inputval + 1); SET @rowcount2 = @@ROWCOUNT; END/); # The first placeholder (?) in this prepared statement represents # the value that's supplied as the procedure's input parameter. # The second and third placeholders are used to capture the # procedure's output parameter values. my $sth1 = $dbh->prepare ("{call PROC_INSERT_TABLES(?, ?, ?)}"); my $i = 1; my $sqlserverrowcount; my $sqlserverrowcount2; # Bind value for the first placeholder (the procedure's input parameter). $sth1->bind_param(1, $i); # $sqlserverrowcount and $sqlserverrowcount2 store the row count # values returned by the procedure's output parameters. $sth1->bind_param_inout(2, \$sqlserverrowcount, 1); $sth1->bind_param_inout(3, \$sqlserverrowcount2, 1); # Execute the prepared statement. $sth1->execute(); # Produce a cumulative total for the number of rows affected # by both INSERT statements. $sqlserverrowcount = $sqlserverrowcount + $sqlserverrowcount2; print "Rows affected (Cumulative \@ROWCOUNT) = $sqlserverrowcount\n"; # The rows method returns the number of rows affected by the last # row affecting statement. It's unaware that the procedure contained # more than one INSERT statement. print "Rows affected (DBI rows method) = ", $sth1->rows, "\n"; $dbh->do(q/DROP PROCEDURE PROC_INSERT_TABLES/); $dbh->do(q/DROP TABLE PERL_SAMPLE_TABLE/); $dbh->disconnect;
Typical output from the above script is:
Rows affected (Cumulative @ROWCOUNT) = 2 Rows affected (DBI rows method) = 1
Note It is common practice to put SET NOCOUNT ON at the front of procedures, as this prevents DONE_IN_PROC TDS messages and speeds up procedures. If you do this, the DBI rows method returns -1, because the SQL Server ODBC driver does not get the count. The procedure in the example gets around this problem, as @@ROWCOUNT is still set.
Procedures generating multiple sesult sets
Procedures can contain multiple SELECT statements. They are therefore capable of generating an unknown number of result sets. The following script shows how to handle multiple result set generating statements by using the boolean DBD::ODBC method odbc_more_results.
odbc_more_results lets your script check whether there is another result set to be fetched. It returns false when no more results are available.
Note also that output parameters are not returned until odbc_more_results returns false.
To determine whether to return true or false, odbc_more_results calls SQLMoreResults. There are some situations where DBD::ODBC will automatically call SQLMoreResults without the need for odbc_more_results. If the previous SQL statement that executed was a non result-set generating statement, such as an INSERT statement, DBD::ODBC calls SQLMoreResults for you. This triggers the execution of the next statement in the procedure. If the previous statement generated a result set, your script needs to call SQLMoreResults explicitly by using odbc_more_results.
For example in the sample procedure, the first SELECT statement gets executed as a result of DBD::ODBC calling SQLMoreResults:
INSERT INTO PERL_SAMPLE_TABLE VALUES (@inputval); SELECT i FROM PERL_SAMPLE_TABLE; SELECT i FROM PERL_SAMPLE_TABLE WHERE i = @inputval; SELECT @result = i FROM PERL_SAMPLE_TABLE WHERE i = @inputval;
The second and third SELECT statements get executed as a result of the script calling SQLMoreResults by using odbc_more_results.
#!/usr/bin/perl -w use strict; use DBI; # Replace datasource_name with the name of your data source. # Replace database_user_name and database_password # with the SQL Server database user name and password. my $data_source = q/dbi:ODBC:datasource_name/; my $user = q/database_user_name/; my $password = q/database_password/; my $dbh = DBI->connect($data_source, $user, $password) or die "Can't connect to $data_source: $DBI::errstr"; $dbh->do(q/CREATE TABLE PERL_SAMPLE_TABLE (i INTEGER)/); $dbh->do(q/CREATE PROCEDURE PROC_MULTIPLE_RESULT_SETS (@inputval int, @result int OUTPUT) AS BEGIN -- Insert the input parameter value into the test table. INSERT INTO PERL_SAMPLE_TABLE VALUES (@inputval); SELECT i FROM PERL_SAMPLE_TABLE; SELECT i FROM PERL_SAMPLE_TABLE WHERE i = @inputval; -- This SELECT statement returns one value. Capture -- the value with the procedure's output parameter. SELECT @result = i FROM PERL_SAMPLE_TABLE WHERE i = @inputval; END /); my $sth1 = $dbh->prepare ("{call PROC_MULTIPLE_RESULT_SETS(?, ?)}"); my $i = 1; my $output = 0; while ($i < 4) { print "Iteration $i\n"; print "============\n"; $sth1->bind_param(1, $i); $sth1->bind_param_inout(2, \$output, 100); $sth1->execute(); print " Rows affected: ", $sth1->rows, "\n"; # The execute will cause the insert in the procedure to insert a # $i into the table. DBD::ODBC will spot this is not a result-set # generating statement and call the ODBC API SQLMoreResults for you # thus causing the first select to run. # my $rs=1; do { # Fetch and display the result sets generated by the first two # SELECT statements in the procedure. print " result-set ", $rs++, ":\n"; while (my (@row) = $sth1->fetchrow_array) { print "\t", join (", ", @row) , "\n"; } print " (calling SQLMoreResults)\n"; } while ($sth1->{odbc_more_results}); # Check to find out if there's more # data to be fetched. # All result sets have been retrieved. The procedure will now # have returned the output parameter value. print " result-set ", $rs++, "\n\t$output\n" if ($output != 0); $i++; print "\n"; } $dbh->do(q/DROP PROCEDURE PROC_MULTIPLE_RESULT_SETS/); $dbh->do(q/DROP TABLE PERL_SAMPLE_TABLE/); $dbh->disconnect;
Typical output from the above script is:
Iteration 1
============
Rows affected: 1
result-set 1:
1
(calling SQLMoreResults)
result-set 2:
1
(calling SQLMoreResults)
result-set 3
1
Iteration 2
============
Rows affected: 1
result-set 1:
1
2
(calling SQLMoreResults)
result-set 2:
2
(calling SQLMoreResults)
result-set 3
2
Iteration 3
============
Rows affected: 1
result-set 1:
1
2
3
(calling SQLMoreResults)
result-set 2:
3
(calling SQLMoreResults)
result-set 3
3
PRINT statement and status messages
PRINT statements let you return a user-defined message from a procedure. They help you to troubleshoot a procedure. For example, PRINT statements let you check data values or embed trace messages to isolate problem areas in a procedure.
To capture PRINT statement output in a Perl script, you need to create a custom error handler. The standard ODBC diagnostic mechanism does not retrieve PRINT statement output.
SQL Server commands such as BACKUP and DBCC also generate status messages to report their progress. You also need to create an error handler if you want to intercept these messages.
To replace the default error handler, set the odbc_err_handler database handle attribute to a reference to a subroutine that will act as the replacement error handler. The following script shows you how to do this.
#!/usr/bin/perl -w use strict; use DBI; # Replace datasource_name with the name of your data source. # Replace database_user_name and database_password # with the SQL Server database user name and password. my $data_source = q/dbi:ODBC:datasource_name/; my $user = q/database_user_name/; my $password = q/database_password/; my $dbh = DBI->connect($data_source, $user, $password) or die "Can't connect to $data_source: $DBI::errstr"; # Catch and display status messages with this error handler. sub err_handler { my ($sqlstate, $msg, $nativeerr) = @_; # Strip out all of the driver ID stuff $msg =~ s/^(\[[\w\s:]*\])+//; print $msg; print "===> state: $sqlstate msg: $msg nativeerr: $nativeerr\n"; return 0; } $dbh->{odbc_err_handler} = \&err_handler; $dbh->{odbc_exec_direct} = 1; my $sql = q/CREATE PROCEDURE PROC_PRINT_MESSAGES AS PRINT 'START'; SELECT 1; PRINT 'END';/; $dbh->do($sql); my $sth = $dbh->prepare("{ call PROC_PRINT_MESSAGES }"); $sth->execute; do { while (my @row = $sth->fetchrow_array) { if ($row[0] eq 1) { print "Valid select results with print statements\n"; } } } while ($sth->{odbc_more_results}); $dbh->do(q/drop procedure PROC_PRINT_MESSAGES/); $dbh->disconnect;
The following line in the script forces DBD::ODBC to use SQLExecDirect instead of SQLPrepare then SQLExecute.
$dbh->{odbc_exec_direct} = 1;
This prevents certain versions of the Microsoft SQL Server ODBC driver (you use this driver if you access SQL Server with the ODBC-ODBC Bridge) from generating errors when the procedure the script contains is executed. The errors are similar to the following:
(SQL-42S02)(DBD: Execute immediate failed err=-1) at myscript.pl line 6. DBD::ODBC::st execute failed: [Microsoft][ODBC SQL Server Driver]Invalid cursor state (SQL-24000)(DBD: dbd_describe/SQLNumResultCols err=-1) at myscript.pl line 12. DBD::ODBC::st fetchrow_array failed: (DBD: no select statement currently executing err=-1) at myscript.pl line 14.
Multiple Active Statements
In SQL Server 2005 and later, there is a feature called MARS (Multiple Active Result Sets), which allows multiple active SELECT statements. If you're using our SQL Server ODBC driver and want to use MARS, add this line to your ODBC data source in odbc.ini:
Mars_Connection = Yes
Alternatively, add MARS_Connection=Yes to the connection string. For example:
my $dbh = DBI->connect("dbi:ODBC:DSN=$data_source;MARS_Connection=Yes;") or die "Can't connect to $data_source: $DBI::errstr";
Using this method will also turn on MARS on the connection if you're connecting to SQL Server 2005 or later with the Microsoft SQL Server Native Client ODBC driver.
Microsoft SQL Server 2000 and earlier can support Multiple Active Statements if you use a server side cursor. If your version of either SQL Server or the Microsoft SQL Server ODBC driver does not support MARS, and you have no alternative other than to use Multiple Active Statements, you can enable this workaround by:
- Setting setting
SQL_ROWSET_SIZEto a value > 1 in your connect method. For example:my $dbh = DBI->connect("dbi:ODBC:$data_source", $user, $password) or die "Can't connect to $data_source: $DBI::errstr"; $dbh->{odbc_SQL_ROWSET_SIZE} = 2;
- Setting the cursor type to
SQL_CURSOR_DYNAMICin your connect method. For example:my $dbh = DBI->connect("dbi:ODBC:$data_source", $user, $password, {odbc_cursortype => 2}) or die "Can't connect to $data_source: $DBI::errstr";
The following script shows how to enable MARS from DBD::ODBC and provides workarounds for SQL Server 2000 and earlier, if you have no alternative other than to use Multiple Active Statements.
#!/usr/bin/perl -w use strict; use DBI; # # Microsoft SQL Server does not by default allow Multiple Active Statements # i.e. it does not allow you to create a second result set on another # statement whilst a result-set is active on another statement. # In Microsoft SQL Server 2005 and later, there is a feature called Multiple # Active Result Sets (MARS), which allows multiple active SELECT # statements, but has some implications if you are also doing transactions. # (See http://msdn.microsoft.com/en-us/library/ms345109.aspx.) # To enable MARS from DBD::ODBC, add "MARS_Connection=Yes" # to the connection string as in: # # DBI->connect('dbi:ODBC:DSN=mydsn;MARS_Connection=Yes;'); # # Microsoft SQL Server 2000 and earlier can support Multiple Active Statements # if you use a server side cursor, but the normal ways of enabling server # side cursors are not available in DBD::ODBC. A workaround was found by # setting SQL_ROWSET_SIZE to a value > 1. However, # a) although this persuades Microsoft SQL Server to create a server side cursor # server-side cursors are slower than static cursors. # b) it is slightly dangerous, as if you do not consume all the result-set # or call finish, you can hang the Microsoft SQL Server ODBC driver. # This is easily demonstrated via the PHP interface # /developer/languages/php/apache_odbc.html#appb2 but # we have never reproduced it in DBD::ODBC - perhaps because finish # is called for you. # c) this workaround only works because DBD::ODBC does not use # SQLExtendedFetch - if that changed it would undoubtably break. # # A more reliable way of doing this is by setting the cursor type # to SQL_CURSOR_DYNAMIC. You can do this in the connect method # as below. my $data_source = q/datasource_name/; my $user = q/database_user_name/; my $password = q/database_password/; # Use this form of connect to get Multiple Active Statements # in SQL Server 2005 and later: # my $dbh = DBI->connect("dbi:ODBC:DSN=$data_source;MARS_Connection=Yes;") or die "Can't connect to $data_source: $DBI::errstr"; # # SQL Server 2000 and earlier: # #my $dbh = DBI->connect("dbi:ODBC:$data_source", $user, $password, # {odbc_cursortype => 2}) # or die "Can't connect to $data_source: $DBI::errstr"; # Alternative method to get MAS for SQL Server 2000 and earlier: # # Uncomment the next line to use the workaround to get MAS. # Better method is to use odbc_cursor_type. # #$dbh->{odbc_SQL_ROWSET_SIZE} = 2; $dbh->do(q/create table "mas" (a integer)/); $dbh->do(q/create table "mas2" (a integer)/); $dbh->do(q/insert into "mas" values (1)/); $dbh->do(q/insert into "mas2" values (2)/); my $sth = $dbh->prepare(q/select * from "mas"/); # If you are connecting to SQL Server 2000 or earlier and have not # done one of the following: # # a) Set a dynamic cursor (see first commented out connect # call, above). # # b) Uncommented the SQL_ROWSET_SIZE workaround (see commented # out code above) then you will get an error similar to: # # "DBD::ODBC::st execute failed: [unixODBC][Microsoft # [SQL Native Client] Connection is busy with results for # another command (SQL-HY000) at mas.pl line 92." # # You also need to use one of these workarounds if you are using a # non-SQL Native Client version of the Microsoft SQL Server ODBC # driver. $sth->execute; my $sth2 = $dbh->prepare(q/select * from "mas2"/); $sth2->execute; my $col = $sth->fetchrow_array; print "Column from first result-set, val = $col\n"; my $othercol = $sth2->fetchrow_array; print "Column from second result-set, val = $othercol\n"; $sth->finish; $sth2->finish; $dbh->do(q/drop table "mas"/); $dbh->do(q/drop table "mas2"/); $dbh->disconnect;
For more information about MAS, refer to our Multiple Active Statements (MAS) and DBD::ODBC tutorial.
Faster inserting
These examples use a table containing 5 columns: an integer, a char(30), a varchar(255), a timestamp, and a float.
The simplest code to populate this table is:
my $sql; for (my $i = 0; $i <50000; $i++) { sql = "insert into perf values (" . $i . ", 'this is a char thirty'" . ",'this is a varchar 255', {ts '2008-08-01 11:12:13.123'}, " . $i * 1.1 . ")"; my $sth = $dbh->prepare($sql); $sth->execute; }
Here, we construct the SQL INSERT statement once for each row, and call SQLExecDirect once for each row. The problem with this code is that the database has to parse and prepare the INSERT statement once per row; this can be time consuming.
A much more efficient method is to use a parameterised insert. Here, parameters are used in place of the column data. Instead of the SQL shown above, we would use:
insert into perf values (?,?,?,?,?)
We prepare this SQL once (using the prepare method), bind the parameters with the bind_param method, and then just keep calling the execute method. For some columns, we change the data bound each time. For example:
my $sth = $dbh->prepare(q/insert into perf values (?,?,?,?,?)/); $sth->bind_param(2, 'this is a char thirty'); $sth->bind_param(3, 'this is a varchar 255'); $sth->bind_param(4, '2008-08-01 11:12:13.123'); for (my $i = 0; $i < 50000; $i++) { $sth->bind_param(1, $i); $sth->bind_param(5, $i*1.1); $sth->execute; }
Another change we could make is to use arrays of parameters (for an example, refer to the Easysoft ODBC-ODBC Bridge performance white paper), but doing this does not seem to make any real difference to performance.
Alternative Perl SQL Server solution
The ODBC-ODBC Bridge is another product from Easysoft that provides Perl to SQL Server connectivity from UNIX and Linux platforms.
The ODBC-ODBC Bridge is available on more platforms than our SQL Server ODBC driver.
The ODBC-ODBC Bridge is an ODBC driver for UNIX and Linux that accesses SQL Server by using the Microsoft SQL Server ODBC driver on Windows.
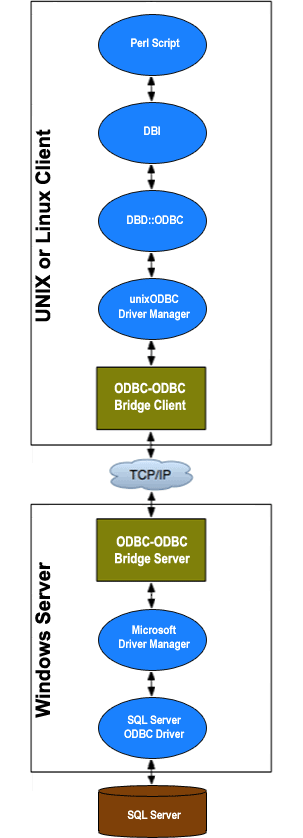
What you need to install
The ODBC-ODBC Bridge allows ODBC applications on one machine to access ODBC drivers on another machine.
The ODBC-ODBC Bridge consists of a client ODBC driver (which you install on the machine where Perl is running) and a server (which you install on a Windows machine where the Microsoft SQL Server ODBC driver is installed).
Refer to the following example to find out what you need to install on your client and server machines:
-
Client machine
This is the machine where you want to run your Perl. You need to have installed:
- Perl The minimum version required for Perl's DBI module.
- Perl DBI The database independent interface for Perl. You can get this from CPAN.
-
Perl DBD::ODBC The ODBC driver for DBI. You can get this from CPAN.
There are other ways of accessing Microsoft SQL Server from Perl such as by using the XML-ODBC Server, but this tutorial concerns itself with DBI and DBD::ODBC.
- ODBC-ODBC Bridge client The ODBC-ODBC Bridge client is an ODBC driver that talks to the ODBC-ODBC Bridge server and therefore your remote ODBC data source. You need to install the ODBC-ODBC Bridge client and the unixODBC Driver Manager. ODBC-ODBC Bridge distributions include the unixODBC Driver Manager. There is no need to install the ODBC-ODBC Bridge server on this machine. Refer to the ODBC-ODBC Bridge manual for installation instructions.
For help with installing Perl DBI, DBD::ODBC and the ODBC-ODBC Bridge client, refer to Enabling ODBC support in Perl with Perl DBI and DBD::ODBC.
-
Server machine
This is the machine where you have (or can install) an ODBC driver for the database you want to access. You need to install:
- ODBC driver For this tutorial, you need the Microsoft SQL Server ODBC driver, and it's available in Microsoft Data Access Components (MDAC) and the Microsoft SQL Server Native Client. You don't need to install the Microsoft SQL Server ODBC driver on the same machine as your SQL Server database.
-
ODBC-ODBC Bridge server. The ODBC-ODBC Bridge server is an ODBC application, which accepts connections from the ODBC-ODBC Bridge client and relays them to your target ODBC data source. You need to license the ODBC-ODBC Bridge server, and trial licenses may be obtained during the installation. Refer to the ODBC-ODBC Bridge manual for installation instructions.
In the following sections, we refer to the server machine as
windows_server.
Data sources
You will find a lot of very useful information on ODBC connection attributes and data sources in Perl DBD::ODBC drivers, data sources and connection.
An ODBC data source is a named resource that the application passes to the ODBC Driver Manager. The data source tells the Driver Manager which ODBC driver to load and which connection attributes to use. You don't have to create data sources, as DSN-less connections provide an alternative way to connect, and you will find details on this in the first tutorial.
With the ODBC-ODBC Bridge, there are two data sources to consider. The first data source is an ODBC-ODBC Bridge client one on your client machine. This data source tells the Driver Manager to use the ODBC-ODBC Bridge client and sets a number of attributes for the ODBC-ODBC Bridge client. The attributes tell the ODBC-ODBC Bridge client which server to connect to and which data source on the remote machine to use.
A typical ODBC-ODBC Bridge client data source looks like this:
[mydatasource] # Driver tells the driver manager which ODBC driver to use Driver = ODBC-ODBC Bridge # Description is a description of this data source Description = connect to SQL Server on windows # ServerPort is the name of the machine where the ODBC-ODBC Bridge server is running # and the port on which it is listening. The default port is 8888. ServerPort = windows_server:8888 # LogonUser is a valid user account on the windows_server machine # LogonAuth is LogonUser's password LogonUser = my_windows_user_name LogonAuth = LogonUsers_password # TargetDSN is the name of the data source on windows_server to connect to TargetDSN = windows_server_dsn # TargetUser and TargetAuth are synonomous with the ODBC connection # attributes UID and PWD and specify the user and password to use for # the database login - if required. # TargetUser = db_user_name TargetAuth = TargetUsers_password
We describe these attributes in the following sections. When using Perl DBI, you don't need to specify TargetUser and TargetAuth in the data source, as these are passed in to the DBI->connect method.
Authentication
There are two levels of authentication you need to be aware of:
-
ODBC-ODBC Bridge server authentication
By default, the ODBC-ODBC Bridge server needs to authenticate the client and become the specified user on the
windows_servermachine. To do this, the ODBC-ODBC Bridge client needs to specify the data source attributesLogonUserandLogonAuth.LogonUseris the name of a user who has permission to log on locally to thewindows_servermachine andLogonAuthis that user's password. A user who has log on locally permissions is defined as a user who can log on at the console ofwindows_server. IfLogonUserandLogonAuthare valid, the ODBC-ODBC Bridge server becomes theLogonUser.Note You can turn off ODBC-ODBC Bridge server authentication, but this has various implications (refer to the ODBC-ODBC Bridge manual).
-
Microsoft SQL Server authentication
When you create a Microsoft SQL Server data source in the Windows ODBC Data Source Administrator, you have the choice of:
-
With Integrated Windows authentication
This is sometimes called trusted connections. In this situation, Microsoft SQL Server examines the user on the Windows machine that's communicating with it and no SQL Server user name or password are required.
-
With SQL Server authentication using a login ID and password entered by the user
SQL Server requires a database user name and password that your database administrator will have set up. If this is your situation, the ODBC connection attributes
UIDandPWDmust be specified at the client end (you do this with the second and third arguments toDBI->connect).
-
At this stage, an example might help illustrate SQL Server authentication. Suppose you have an account on the windows_server machine; your user name is Fred Bloggs and your password is mypassword. Your database administrator has set up the SQL Server instance with SQL Server authentication active, and has set you up an account for the database with user name dbuser and password dbpassword. You need to set the ODBC-ODBC Bridge data source attributes LogonUser and LogonAuth to Fred Bloggs and mypassword and call DBI->connect with dbuser and dbpassword.
ServerPort
The ServerPort attribute tells the ODBC-ODBC Bridge client ODBC driver which server to connect to. ServerPort is the name or IP address of the server machine where the ODBC-ODBC Bridge server service is running and the port the server is listening on. The port defaults to 8888 in the ODBC-ODBC Bridge server configuration. This is not the port your database engine is listening on. Separate the server machine from the port with a colon (:) in the ServerPort attribute value. For example, windows_server:8888.
The ODBC-ODBC Bridge server is configurable through an HTTP interface. Supposing your ODBC-ODBC Bridge server is installed on windows.mycompany.local, you can access the ODBC-ODBC Bridge server administration interface using the URL http://windows.mycompany.local:8890.
Note On Windows, the ODBC-ODBC Bridge server installation sets the HTTP interface port to 8890, by default. This default setting can be changed during the ODBC-ODBC Bridge server installation and through the HTTP interface's Configuration section.
Target data source
The TargetDSN attribute tells the ODBC-ODBC Bridge client which data source on the remote server you want to access. This must be the name of a system data source as the ODBC-ODBC Bridge server can only access system data sources. (To create a system data source, in the Microsoft ODBC Data Source Administrator, select the System DSN tab, and then choose Add.)
For more information about creating a system DSN on Windows, refer to the ODBC-ODBC Bridge manual.
Where to go now
Use unixODBC's isql program (included in the ODBC-ODBC Bridge distribution) to test your ODBC-ODBC Bridge client data source. Then test that you can access your data source from Perl.